🚶 Detección de puntos clave del cuerpo con Mediapipe en Python – Pose Landmark Detection
¡Hola, hola, Omesitos! En este video vamos a retomar una de las soluciones que nos ofrece MediaPipe para detección de puntos clave en el cuerpo: Pose Landmark Detection. Veremos como aplicarlo en imágenes, videos y videostreming.¡Empecemos!
¿Qué es la detección de puntos clave del cuerpo?
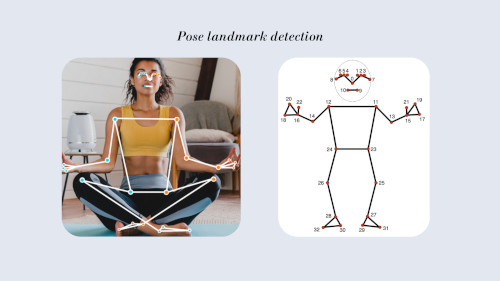
El landmark detection es la detección de distintos puntos clave distribuidos en el cuerpo humano, mediante un modelo de machine learning. Dicho modelo permitirá extraer una determinada cantidad de puntos. En MediaPipe, los modelos para aplicar landmark detection pueden extraer 33 puntos.
🔧 Instalación de MediaPipe
Para llevar a cabo esta práctica debemos instalar MediaPipe, a través de:
pip install mediapipe
Puedes verificar su instalación y versión con: pip freeze
Nota: A continuación te dejo la programación usada en el video. Si quieres ver el paso a paso explicado con más detalle, ¡no te pierdas el video completo!
🚶 Pose Landmark detection en imágenes
import cv2
import mediapipe as mp
from mediapipe.tasks.python import vision
from mediapipe.tasks.python import BaseOptions
# Especificar la configuración
options = vision.PoseLandmarkerOptions(
base_options=BaseOptions(model_asset_path="pose_landmarker_lite.task"),
running_mode=vision.RunningMode.IMAGE)
landmarker = vision.PoseLandmarker.create_from_options(options)
# Leer la imagen de entrada
image = cv2.imread("./Inputs/02_image.jpg")
h, w, _ = image.shape
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_rgb = mp.Image(image_format=mp.ImageFormat.SRGB, data=image_rgb)
# Obtener los resultados
pose_landmarker_result = landmarker.detect(image_rgb)
print(pose_landmarker_result)
for lm in pose_landmarker_result.pose_landmarks:
#print(lm)
#print(lm[26])
#x_right_knee = int(lm[26].x * w)
#y_right_knee = int(lm[26].y * h)
#cv2.circle(image, (x_right_knee, y_right_knee), 8, (0, 0, 255), -1)
for each_lm in lm:
if each_lm.visibility > 0.9:
x_each_lm = int(each_lm.x * w)
y_each_lm = int(each_lm.y * h)
cv2.circle(image, (x_each_lm, y_each_lm), 5, (0, 255, 255), -1)
cv2.imshow("Image", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
🚶 Pose Landmark detection aplicado en Video
import cv2
import mediapipe as mp
from mediapipe.tasks.python import vision
from mediapipe.tasks.python import BaseOptions
# Especificar la configuración
options = vision.PoseLandmarkerOptions(
base_options=BaseOptions(model_asset_path="pose_landmarker_lite.task"),
running_mode=vision.RunningMode.VIDEO)
landmarker = vision.PoseLandmarker.create_from_options(options)
# Leer el video de entrada
cap = cv2.VideoCapture("./Inputs/01_video.mp4")
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
fps = cap.get(cv2.CAP_PROP_FPS)
for frame_index in range(int(frame_count)):
ret, frame = cap.read()
if ret == False:
break
h, w, _ = frame.shape
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_rgb = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame_rgb)
# Calcular la marca temporal del frame actual (en milisegundos)
frame_timestamp_ms = int(1000 * frame_index / fps)
# Obtener los resultados
pose_landmarker_result = landmarker.detect_for_video(frame_rgb, frame_timestamp_ms)
for lm in pose_landmarker_result.pose_landmarks:
for each_lm in lm:
if each_lm.visibility > 0.9:
x_each_lm = int(each_lm.x * w)
y_each_lm = int(each_lm.y * h)
cv2.circle(frame, (x_each_lm, y_each_lm), 3, (0, 255, 255), -1)
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()
🎞️ Pose Landmark detection aplicado en Video Stream
import cv2
import mediapipe as mp
from mediapipe.tasks.python import vision
from mediapipe.tasks.python import BaseOptions
import time
result_list = []
# Función callback para procesar los resultados
def res_callback(result, output_image, timestamp_ms):
result_list.append(result)
# Especificar la configuración
options = vision.PoseLandmarkerOptions(
base_options=BaseOptions(model_asset_path="pose_landmarker_lite.task"),
running_mode=vision.RunningMode.LIVE_STREAM,
result_callback=res_callback)
landmarker = vision.PoseLandmarker.create_from_options(options)
# Leer el video de entrada
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
while True:
ret, frame = cap.read()
if ret == False:
break
h, w, _ = frame.shape
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_rgb = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame_rgb)
# Obtener los resultados
landmarker.detect_async(frame_rgb, time.time_ns() // 1_000_000)
if result_list:
for lm in result_list[0].pose_landmarks:
for each_lm in lm:
if each_lm.visibility > 0.9:
x_each_lm = int(each_lm.x * w)
y_each_lm = int(each_lm.y * h)
cv2.circle(frame, (x_each_lm, y_each_lm), 3, (0, 255, 255), -1)
result_list.clear()
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()
Y eso ha sido todo por este post, Omesitos.
Espero que les haya resultado útil y que se animen a probarlo.
📌 No olviden revisar el video si desean ver todo el paso a paso en acción.
¡Nos vemos en el siguiente post!




